Introduction
Part 1 - Inline scripting and external assemblies
Part 2 - XSLT Call Templates and custom extensions
Part 3 - Cascading Functoids
This is the third of three articles about BizTalk mapping with external assemblies. External assemblies or helper classes are used by BizTalk's mapping engine (XSLT) automatically, and they can also be used explicitly by the developer. Just as in an orchestration, a developer may find a requirement that the built in mapping tools ("functoids") do not address and in this case judicious use of a helper class can be very... helpful.
While these articles are not an introduction to mapping if you have a little experience with the BizTalk mapper and a little experience with XSLT you should be able to follow along.
Part 1, introduces inline C# scripting, its limitations, and also introduces the scenario of using an external assembly (helper class) automatically. Part 2, demonstrates using a map's custom extension property, which allows us to explicitly access external assemblies. Part 3, this article, will build on this discussion and highlight potential caveats about using cascading functoids; when the output of one functoid is the input to another functoid(s).
Validating Maps that use Cascading Functoids
Whether a transformation is simple or complex, I often find validating a BizTalk map and viewing the XSLT output is beneficial. Below is an example of a simple map containing a cascading functoid; a function that calls another function. If we review the resulting XSL file the output is as expected. Yet, the output from maps containing cascading functoids that output to multiple targets (be it other functoids or other nodes) does not generate as I would expect.
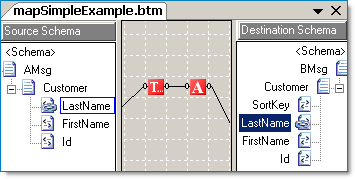
The XSLT output from this map is as expected. The variable v1 contains the right trimmed string and serves as input to the UpperCase functoid, the output of which is assigned to v2. The value of v2 is then contained in the LastName node.
<xsl:template match="/s0:AMsg">
<xsl:variable name="var:v1"
select="userCSharp:StringTrimRight(string(Customer/LastName/text()))" />
<xsl:variable name="var:v2"
select="userCSharp:StringUpperCase(string($var:v1))" />
<ns0:BMsg>
<Customer>
<LastName>
<xsl:value-of select="$var:v2" />
</LastName>
</Customer>
</ns0:BMsg>
</xsl:template>
Note: The built in functoids imbed inline C# code. We can use the "userCSharp:" XSL namespace ourselves when constructing XSLT functoids. We will see an example below.
Functoids with Multiple Outputs
The XSLT story changes when we examine output from the BizTalk mapper when using a functoid that is connect to more than one node (or cascading functoid). It turns out that in the example below, you will see that the entire functoid chain is executed twice. Once for the SortKey node, and once for the LastName node.

Typically a functoid with multiple outputs will be executed once for each output. In this example, the entire functoid chain is executed once for each connection. Imagine using a helper class to get a database value, if one is not careful the same database helper method might be executed more than one time! The XSLT code below is what the BizTalk mapper generated for the map above.
<xsl:template match="/s0:AMsg">
<!-- SortKey functoid chain -->
<xsl:variable name="var:v1"
select="userCSharp:StringTrimRight(string(Customer/LastName/text()))" />
<xsl:variable name="var:v2"
select="userCSharp:StringUpperCase(string($var:v1))" />
<!-- LastName functoid chain -->
<xsl:variable name="var:v3"
select="string(Customer/LastName/text())" />
<xsl:variable name="var:v4"
select="userCSharp:StringTrimRight($var:v3)" />
<xsl:variable name="var:v5"
select="userCSharp:StringUpperCase(string($var:v4))" />
<ns0:BMsg>
<Customer>
<SortKey>
<xsl:value-of select="$var:v2" />
</SortKey>
<LastName>
<xsl:value-of select="$var:v5" />
</LastName>
</Customer>
</ns0:BMsg>
</xsl:template>
BizTalk Transformations with Value Caching
Let's expand on the example above. In the map below we have two functoid chains, each go to their respective output element and also to a string concatenation function, which is in turn connected to the SortKey field. Because we want our imagined map to be as efficient as possible we won't be able to completely use BizTalk's drag and drop mapping. We will need to eliminate the multiple connections that go to both the concatenation functoid and to the target fields. One way to do this is by implementing value caching combined with an XSLT call template to eliminate the multiple executions of the same methods. After describing the approach, there will be a short review of the benefits and caveats.
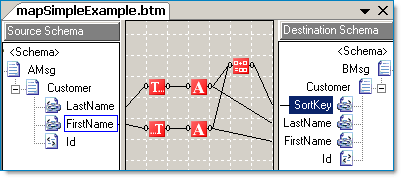
Value Caching with XSLT Call Templates and Inline C#
By looking at the first cut of our hypothetical map above, we can see that the LastName, FirstName, and SortKey target fields are all interconnected. Thus we are going to eliminate all the functoid chains and replace them with a single XSLT call template. In addition we'll add our own standalone C# code.
By adding an inline C# scripting functoid (#1) we can add methods to be called by the XSLT (#2) in the map.

Even though functoid #1 is "floating" the C# code is still included in the map. This is a simple example of some accessor and related functions. They mainly will serve to cache the First and Last Name values so that we don't have to process them twice (Trim + Uppercase). The actual process of processing the string is for example only, the process could equally have been a database call to a helper function via an External Assembly object.
// SortKey: Return LastName + comma + FirstName
//
public string GetSortKey()
{
return System.String.Format("{0},{1}", GetLastName(), GetFirstName());
}
// LastName: Trim + Uppercase
//
public string _lastName = null;
public void SetLastName(string LastName)
{
_lastName = LastName.Trim();
_lastName = LastName.ToUpper();
}
// LastName: Return value
//
public string GetLastName()
{
return _lastName;
}
// FirstName: Trim + Uppercase
//
public string _firstName = null;
public void SetFirstName(string FirstName)
{
_firstName = FirstName.Trim();
_firstName = FirstName.ToUpper();
}
// FirstName: Return value
//
public string GetFirstName()
{
return _firstName;
}
Functoid #2 is an XSLT template, and it will call the C# methods and emit the SortKey, LastName, and FirstName fields. Here is what the XSLT call template looks like, it is quite similar to what we've already seen in the prior articles.
<xsl:template name="CustomerAndSortKeyTemplate">
<!--Customer & SortKey Input -->
<xsl:param name="LastName" />
<xsl:param name="FirstName" />
<!-- Cache and process the last/first name values:
Call C# using the "userCSharp" namespace alias
that the BizTalk mapper itself generated.
Note: These calls return "void" thus, no output! -->
<xsl:value-of select="userCSharp:SetLastName($LastName)"/>
<xsl:value-of select="userCSharp:SetFirstName($FirstName)"/>
<!-- Emit the SortKey, LastName and FirstName fields -->
<!-- SortKey -->
<xsl:element name="SortKey">
<xsl:value-of select="userCSharp:GetSortKey()"/>
</xsl:element>
<!-- LastName (another way to emit a field) -->
<LastName>
<xsl:value-of select="userCSharp:GetLastName()"/>
</LastName>
<!-- FirstName -->
<FirstName>
<xsl:value-of select="userCSharp:GetFirstName()"/>
</FirstName>
</xsl:template>
Summary
Using XSLT and C# caching can be an efficient approach to designing a map that would otherwise unnecessarily consume too much processing bandwidth if the map were solely generated by the default BizTalk Mapper design output.
Some considerations to think about:
- Using XSLT with the BizTalk mapper might require that you or your client have a comfort level about designing the mapping outside of the normal Drag and Drop approach. However, the efficiency of the custom XSLT, and to some degree the straight-forwardness of it may outweigh the amount of design time needed for a complicated Drag and Drop map.
- The XSLT approach is more sensitive to schema changes. A simple map with out XSLT will fail validation (if not outright fail to compile) if a schema changes. However, custom XSLT is ultimately just syntax based on a matching mechanism. There is not compile time validation that the elements being emitted conform to the current target schema.
External Links from MSDN
External Links about BizTalk Mapper Performance
Article Links



